
Real-time and efficient data modeling techniques in MongoDB
While designing the architecture for Sell.Do’s cloud-based call-center reporting dashboard, the main goal was to empower our clients with insights that would help them manage, measure and optimize their teams’ performance. The ability to show hourly, daily, weekly stats was integral to this goal. The simple aggregation pipeline (group-by) in Mongo worked alright in our development environment, but as soon as we tested it on a data set comparable to our production environment, we realized it wasn’t the best approach to go with. Imagine real-time querying on a data-set which is increasing at a rate of 500,000 records per day. Even the efforts to put in optimal indexes didn’t scale at all. We knew we were missing something.
After spending a few hours on researching the best practices in such use-cases, what we realized is that we had a lot of similarities with what large scale enterprise systems deal with on a day-to-day basis: Data-Warehousing. Ralph Kimball, who is widely regarded as one of the original architects of data warehousing, says:“The single most dramatic way to affect performance in a large data warehouse is to provide a proper set of aggregate (summary) records that coexist with the primary base records. Aggregates can have a very significant effect on performance, in some cases speeding queries by a factor of one hundred or even one thousand.”.
We found a lot of use cases in Mongo, wherein developers had to show real-time website visitor analytics and how they implemented them using pre-aggregation techniques. Pre-aggregation typically involves creating one mongo document per unit of time (i.e. a minute, hour, day, week, etc). This unit of time depends on the amount of granularity that you want your stats to have. So, if you have to display data for a particular unit of time, instead of fetching all the child documents and adding their values (aggregation) to generate the desired result, we can just fetch one document and have our data ready in our hands (pre-aggregation).
Allow us to elaborate with an example related to Sell.Do’s call-reporting feature:
The Manager needs to compare how many calls Salesperson and Salesperson B have answered against a particular period of time. Here, we will keep the document uniqueness factor as 1 document per day i.e a document would have a living-scope of 1 day. This typical pre-aggregation mongo document would look like this:
daily_sales_reporting_info: {
_id: some_unique_id,
created_at_date: ISODate("2015-01-01"), #document uniqueness factor
sales_id: another_unique_id, #foreign key
daily_answered: 100,
hourly_answered: {
0: 0,
...
23: 100,
24: 0
}
}
Let’s discuss the use-cases and their solutions now:
- The report asks for daily data for today: Fetch one document per sales -> return daily_answered
- The report asks for daily data for last week: Fetch 7 documents per sales -> aggregate and return daily_answered
As you can see, for a time period of 1 day only one document needs to be fetched with no post-fetch aggregations. For a time period of 7 days, seven documents need to be fetched with minimal post-fetch aggregation. We can pre-aggregate this data to a deeper level by implementing Weekly Sales Reporting Info. It would have a similar model structure but the uniqueness factor would be 1 week i.e a document would have a living-scope of 1 week.
Let’s see how our use-cases look like now:
- The report asks for daily data for today: Fetch 1 daily_sales_reporting_info document per sales -> return daily_answered
- The report asks for daily data for last week: Fetch 1 weekly_sales_reporting_info document per sales -> return daily_answered
Both the queries now perform 1 fetch and 0 post-fetch aggregations. Awesome!
Sell.Do goes one level deeper in its pre-aggregation schema. Not only does it model daily and weekly sales reporting information, but it also models daily and weekly team reporting information. So if our client needs to see call reports across teams, we don’t need to keep adding sales statistics, we just need to fetch 1 document and perform absolutely 0 post-fetch aggregations. How cool is that?
Pre-aggregation can be coupled with a few performance enhancements like applying indexes on the uniqueness factor and foreign key, using atomic increments for document update and purging of old data. It can go even deeper such as up-to-the-minute or up-to-the-second documents. Additionally, this architecture scales smoothly.
Sell.Do pulls extensive data from its pre-aggregation architecture. For example. if the client asks for a comparison of the total talk time across all sales each Wednesday at 7PM (phew!), we have it. Based on these extensive data points, Sell.Do is now able to detect if the percentage of calls missed during a particular duration (for example Saturday afternoons) is more than the average observed in the past, and notify accordingly. In this way, our systems are able to push intelligent notifications to the management so that they can take informed decisions to improve their operations.
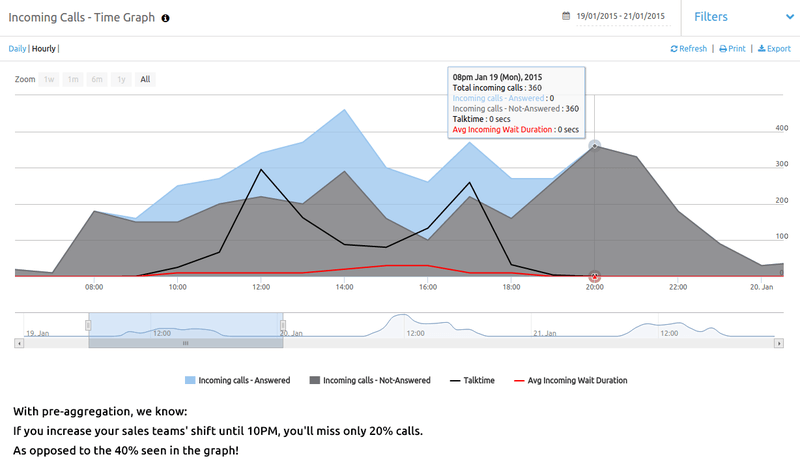
Things to watch out for with pre-aggregation:
Pre-aggregation makes a basic assumption that your reporting architecture is predefined and will not change in the near future. If, after a few days, you decide to make minor tweaks in your reporting, updating all the existing pre-aggregated documents will be a huge mess. Additionally, pre-aggregation makes a lot of updates in your database, so your fetch & update architecture needs to be highly optimized.
Here it is, the secret for lightning-fast and insightful reports is out in the open. Fire away those queries!
By
Tanmay Patil